📖 Creador de Database
🧠 Objetivo del Workflow
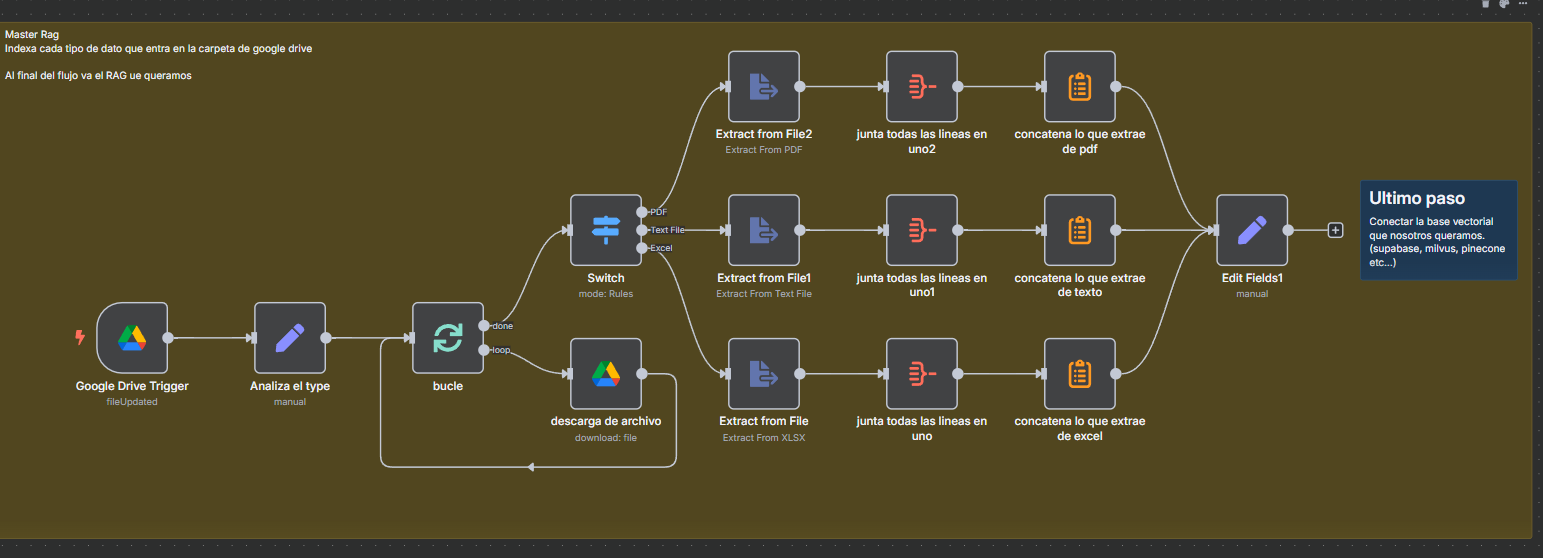
Detectar automáticamente archivos (PDF, Word o Excel) subidos o modificados en una carpeta específica de Google Drive, extraer su contenido de texto, unificarlo y prepararlo para usarlo como entrada de un sistema RAG o de análisis posterior.
🔄 Flujo paso a paso
1. Trigger inicial
- 📂 Google Drive Trigger: Detecta cuándo se sube o actualiza un archivo en la carpeta "RAG N8N".
2. Preparación
- 🧩 Analiza el type: Extrae el
file_idy el tipo MIME del archivo (PDF, DOCX, XLS). - 🔁 bucle: Prepara el procesamiento para cada archivo individualmente.
- 📥 descarga de archivo: Descarga el archivo desde Google Drive.
3. Clasificación por tipo
- 🔀 Switch: Revisa el tipo de archivo (
file_type) y decide el camino: - PDF →
Extract from File2 - Word (DOCX) →
Extract from File1 - Excel (XLS) →
Extract from File
4. Extracción de texto
- 🔍 Extract from File*: Usa el nodo para sacar el texto del archivo.
- 📦 junta todas las lineas en uno*: Reagrupa todas las líneas de texto en un solo bloque.
- 🔗 concatena lo que extrae de *: Une ese bloque de texto en un único string.
5. Resultado final
- 📝 Edit Fields1: Crea una nueva variable llamada
documentoque contiene todo el texto extraído y concatenado.
🧩 ¿Qué falta para completar el sistema?
Puedes conectar Edit Fields1 a un sistema RAG, por ejemplo:
- Un nodo LangChain o agente de IA que use
documentocomo entrada. - O enviar ese texto a una base vectorial como Weaviate.